Social Network Analysis: scoprire le connessioni intorno a un hashtag
Il Festival Internazionale del Giornalismo 2013, in cui Twitter assume un ruolo più che importante, sta trattando ampiamente il tema Data Journalism – il giornalismo basato sull’analisi e l’elaborazione di grandi quantità di dati. In un mondo che cambia continuamente, il data journalism potrà certamente aiutare i giornalisti a conquistare un ruolo sempre più rilevante nella società. L’analisi dei dati presenti sui social network è sempre più utilizzata per ricerche di mercato, marketing politico e ogni altro impiego che coinvolge significative e sempre più ampie fasce di popolazione.
Nell’evento che si è svolto giovedì 25 aprile alle ore 14, presso l’hotel Sangallo, si è parlato di SNA cioè Social Network Analysis. Michael Bauer (Open Knowledge Foundation) ha illustrato il funzionamento di strumenti offerti gratuitamente dalla rete, per identificare le persone su Twitter coinvolte in un determinato argomento (ad esempio #ijf13) analizzando le connessioni che fra loro intercorrono. L’evento è stato caratterizzato dall’uso di alcuni software che prevedono funzionalità non semplici e immediate per i non addetti ai lavori nel campo dell’informatica. Tuttavia l’analisi dei dati non può prescindere dal comprendere almeno la parte introduttiva di concetti come funzioni, algoritmi ed espressioni regolari…
Il tutto ha inizio con il recupero dei dati da Twitter, attraverso le note API messe a disposizione dal social network. Le API non sono altro che delle interfacce di un’applicazione, con le quali un programmatore attinge a determinate funzionalità. Naturalmente i dati, per essere trattati, hanno bisogno di una codifica in un formato. Twitter utilizza il JSON (molto diffuso nel web per la sua semplicità e compattezza).
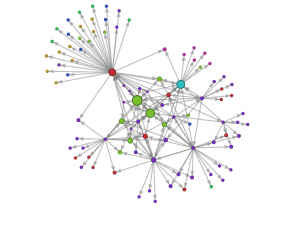
I dati in formato JSON (ricavati dopo aver costruito appositamente un URL che comprenda l’hashtag di partenza), costituiscono l’input del processo di elaborazione spiegato da Michael Baurer. Essi devono essere “trasformati” e sottoposti ad una serie di operazioni. Attraverso OpenRefine, sono stati visualizzati in forma tabellare, le colonne non utili sono state eliminate e vi è stato applicato un algoritmo per mappare tutti gli hashtag (keyword precedute dal carattere “#”) e i riferimenti agli utenti (keyword precedute dal carattere “@”) dei tweet con i rispettivi mittenti. E’ così che vengono creati i gruppi di persone che ruotano intorno ad un determinato argomento. Questo è il nostro output.
A questo punto, le operazioni finali, hanno riguardato l’esportazione dei dati trattati con OpenRefine in un formato comprensibile a Gephi e la configurazione di quest’ultimo. Dopo aver ricevuto le istruzioni per una visualizzazione adatta al nostro scopo, Gephi è stato in grado di mostrarci una rappresentazione con un grafo del nostro output.
Il tutorial nel sito di Data Driven Journalism illustra dettagliatamente le operazioni da svolgere e i software da scaricare per compiere l’intera procedura.
